Harold Erbin and Riccardo Finotello
Physics Department, Università degli Studi di Torino and I.N.F.N. - sezione di Torino
Via Pietro Giuria 1, I-10125 Torino, Italy
Abstract
![]()
We consider a machine learning approach to predict the Hodge numbers of Complete Intersection Calabi-Yau (CICY) 3-folds in the framework of String Theory using two different sets of data: a first dataset containing the configuration matrices of 7890 CICY manifolds (this is the original dataset) and a dataset (the favourable dataset) containing their favourable embedding (at least for most of them).
Related preprint is on ArXiv.
Methodology
We start from the exploratory data analysis to study distribution of data, patterns, correlations and prepare the dataset for the analysis. In this section we do not perform statistical inference but we notice reproducible patterns and key points used in the following analysis.
We then perform a machine learning prediction analysis using several algorithms: we point out pros and cons of each of them, and we discuss the theory behind them and how it can help in improving the results. We use Bayes statistics for hyperparameter optimisation.
Among the algorithms presented we use several linear algorithms and support vector machines as well as decision trees algorithms. We then implement our version of neural networks which are able to improve the final accuracy by more than 25% on the best result obtained with the previous algorithms (we obtain 72% of accuracy using the Gaussian kernel trick in the SVM regressor and 99%+ with the neural networks).
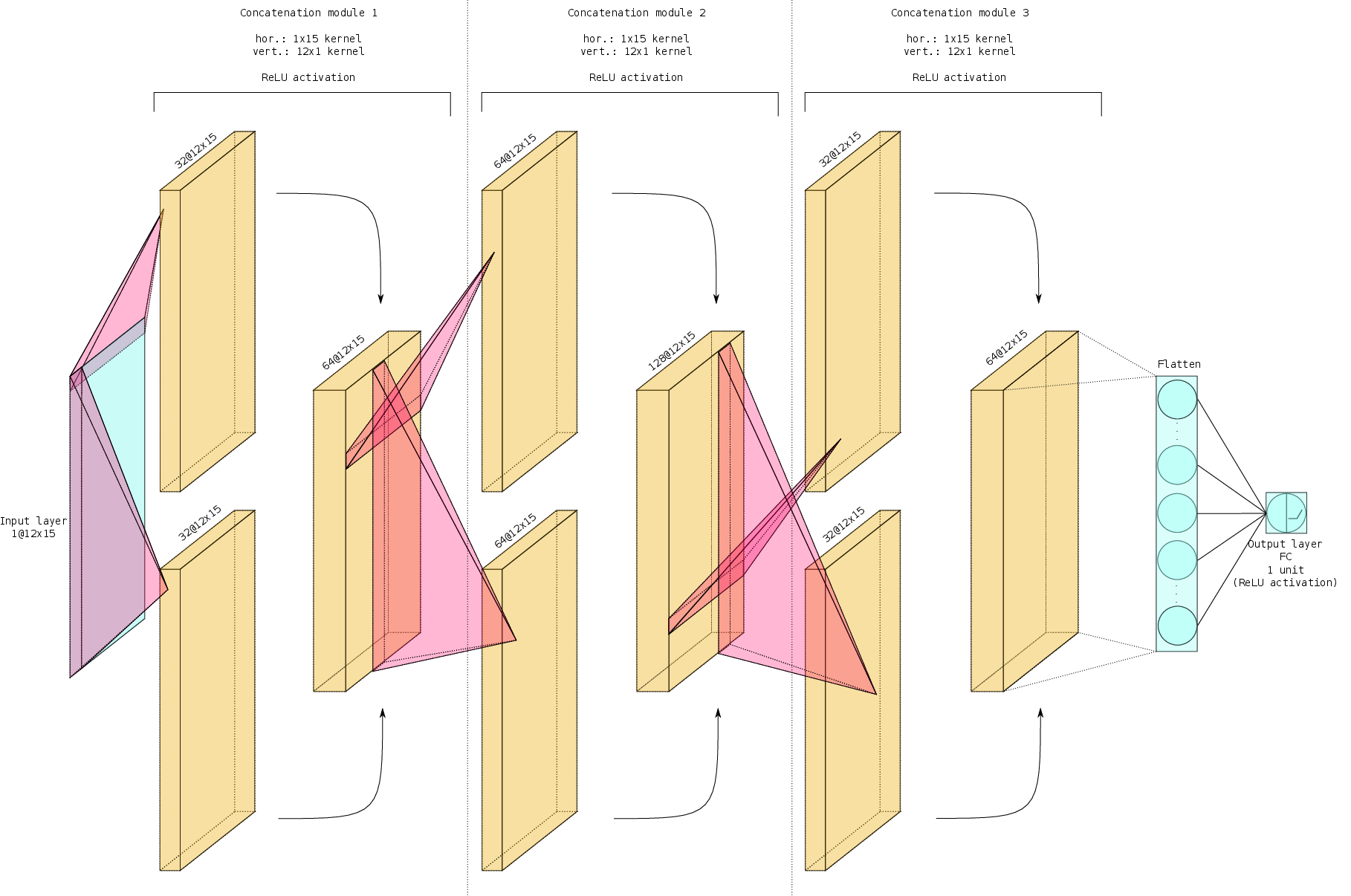
The choice of the architecture of the neural networks was driven by considerations typical of computer vision and object recognition. We use convolutional neural networks to “automatically” build features necessary for inference of the Hodge numbers: we took inspiration from both the classical LeNet originally developed by Y. LeCun in 1998 to which we changed the kernel and used a larger version, and the more modern Inception Network developed by Google. In the last case we considered different convolutions (over rows and columns of the configuration matrix of the CICY manifolds) and concatenated the results found by two concurrent networks: the results reached almost 100% in test accuracy, missing the prediction of only 4 manifolds over more than 780 samples.
Description of the Files
The analysis is divided into different Jupyter notebooks (in this example list, hyperlinks return the version for the original dataset):
- the preanalysis contains a detailed visual analysis of the dataset with outliers detection, clustering and PCA performance comparison, feature engineering and features selection,
- the classical analysis deals with the more “classical” approach of machine learning using linear regression models, support vector machines and decision trees,
- the ConvNet analysis uses convolutional neural networks to build the appropriate architecture to predict the Hodge numbers starting from the configuration matrix of the manifold,
- the transfer learning analysis applies a more refined architecture to the feature engineered set using transfer learning from the previous convolutional models,
- the stacking analysis is an attempt at stacking ensemble learning to improve the results of the previous analysis.
Each IPython notebook is entirely independent and can be run separately. The only real requirement is to first run (at least once) the preanalysis notebook to generate the “analysis-ready” dataset.
Notice that there are several versions of apparently the same notebooks: those named cicy3o… refer to the original dataset, while cicy3f… to the dataset with favourable embeddings. We also present data for the original dataset using only half of the training set and the prediction of the logarithm of the second Hodge number using neural networks.
Installation Prerequisites
In order to run the analysis you will need a Jupyter installation (we used an Anaconda environment) using Python 3.6 at least. Moreover you will be required to install the following packages: